
Learning: Visual Learning
This program explores the enormous potential that still exists towards solving previously impossible problems in machine perception. The recent breakthroughs from the machine learning community have allowed researchers to address new visual learning problems, as well as solve old problems.
The success of deep learning is, in general, attributed to the vast computational resources available, together with large annotated datasets containing millions of images. In spite of these recent developments, there is a lack of understanding of how deep learning works, which invites questions about the convergence, stability and robustness of such models.
This program addresses the important challenges in deep learning, such as effective transfer learning, the role of probabilistic graphical models in deep learning, and efficient training and inference algorithms. Answering these questions will allow us to design and implement strong visual learning systems that will help robots to understand the environment around them.
VL projects
In 2017, the Fundamental deep learning project (VL1) wound up, leaving the Learning for robotic vision project (VL2) as the sole project in this program.
VL1—FUNDAMENTAL DEEP LEARNING
Research leader: Vijay Kumar (RF)
Research team: Gustavo Carneiro (CI), Ian Reid (CI), Chunhua Shen (CI), Basura Fernando (RF), Vijay Kumar (RF), Guosheng Lin (RF), Rafael Felix Alves (PhD), Jian (Edison) Guo (PhD), Ben Harwood (PhD), Zhibin Liao (PhD), Yan Zuo (PhD)
Project aim: Fundamental deep learning is at the core of successfully creating robots that see and is therefore at the core of our Centre’s purpose. Therefore it is imperative that we are actively at the forefront of current machine learning techniques. This includes exploring developing and exploiting, novel network architectures; developing detection and instance- or pixel-level annotations for thousands of open sets of classes; developing weakly supervised, online-trained, zero-shot or unsupervised learning models; developing active learning with and from temporal data.
VL2—LEARNING FOR ROBOTIC VISION
Research leader: Chunhua Shen (CI)
Research team: Ian Reid (CI), Gustavo Carneiro (CI), Chao Ma (RF), Vijay Kumar (RF), Hui Li (PhD), Ben Meyer (PhD), Tong Shen (PhD), Bohan Zhuang (PhD), Yuchao Jiang (Masters by Research)
Project aim: This project is investigating learning that is specific to robotic vision tasks, particularly where there are resource constraints, such as in an embedded vision system. An example of this type of system is COTSbot, which has both storage and power constraints in its operation. To address this, we are exploring avenues such as video segmentation; “any time” algorithms; fast, approximate, asymmetrically computed inference; unsupervised learning; online and lifelong learning for robotic vision; and suitable deep learning techniques.

▴ Example results showing object parsing (left) and semantic segmentation (right)
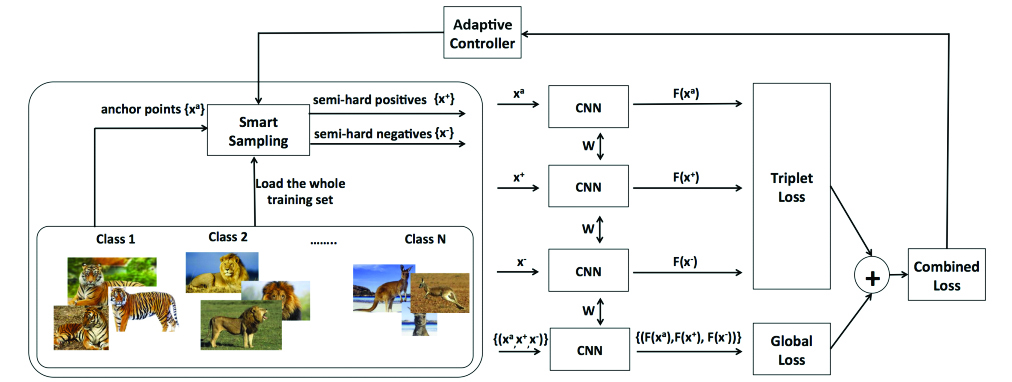
▴ This proposed deep metric learning model is capable of quickly searching an entire training set to select effective training samples.
Key Results in 2017
A unified framework was proposed to tackle the problem of robots reading text in the wild.
In contrast to existing approaches that consider text detection and recognition as two distinct tasks and tackle them one by one, the proposed framework settles these two tasks concurrently. The whole framework can be trained end-to-end, requiring only images, ground-truth bounding boxes and text labels. Published in International Conference on Computer Vision (ICCV2017).
We presented RefineNet, a generic multi-path refinement network that explicitly exploits all the information available along the down-sampling process in a fully convolutional network, enabling high-resolution prediction using long-range residual connections. Published in IEEE Conf. Computer Vision and Pattern Recognition (CVPR2017).
Joint organisation of the workshop “Deep Learning for Robotic Vision” that happened in conjunction with Computer Vision and Pattern Recognition (CVPR 2017) – a fantastic team effort involving lots of people from Adelaide and QUT.
Large-scale datasets have driven the rapid development of deep neural networks for visual recognition.
However, annotating a massive dataset is expensive and time-consuming. Web images and their labels are, in comparison, much easier to obtain, but direct training on such automatically harvested images can lead to unsatisfactory performance, because the noisy labels of Web images adversely affect the learned recognition models. To address this drawback we propose an end-to-end weakly-supervised deep learning framework which is robust to the label noise in Web images. Published in IEEE Conf. Computer Vision and Pattern Recognition (CVPR2017).
Joint publication between Adelaide and Monash on a new method for deep metric learning that is potentially useful for deep learning optimisation methods used by all nodes of the centre: Ben Harwood, Vijay Kumar, Gustavo Carneiro, Ian Reid, Tom Drummond. Smart Mining for Deep Metric Learning. International Conference on Computer Vision (ICCV 2017).